Chapter 3 Initial Data Analysis
In Chapter 2, we mentioned that data analysis includes initial data analysis (IDA). There are various definitions of IDA, much like there are numerous definitions for EDA. Some people would be practising IDA without explicitly realising that it is IDA. Or in other cases, a different name is used to describe the same process, such as Chatfield (1985) referring to IDA also as “initial examination of data” and Cox & Snell (1981) as “preliminary data anlysis” and Rao (1983) as “cross-examination of data.” So what is IDA?
The two main objectives for initial data analysis are:
- data description, and
- model formulation.
IDA differs from the main analysis (i.e. usually fitting the model, conducting significance tests, making inferences or predictions). IDA is often unreported in the data analysis reports or scientific papers due to it being “uninteresting” or “obvious.” The role of the main analysis is to answer the intended question(s) that the data were collected for. Sometimes IDA alone is sufficient.
3.1 Data description
Data description should be one of the first steps in the data analysis to assess the structure and quality of the data. We refer them to occasionally as data sniffing or data scrutinizing. These include using common or domain knowledge to check if the recorded data have sensible values. E.g. Are positive values, e.g. height and weight, recorded as positive values with a plausible range? If the data are counts, are the recorded values contain noninteger values? For compositional data, do the values add up to 100% (or 1)? If not is that a measurement error or due to rounding? Or is another variable missing?
In addition, numerical or graphical summaries may reveal that there is unwanted structure in the data. E.g., Does the treatment group have different demographic characteristics to the control group? Does the distribution of the data imply violations of assumptions for the main analysis?
Data sniffing or data scrutinizing is a process that you get better at with practice and have familiarity with the domain area.
Aside from checking the data structure or data quality, it’s important to check how the data are understood by the computer, i.e. checking for data type is also important. E.g.,
- Was the date read in as character?
- Was a factor read in as numeric?
3.1.1 Checking the data type
Example 1: Consider the following data stored as an excel sheet.
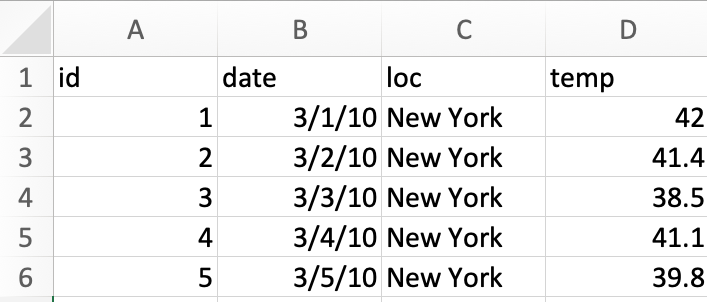
We read this data into R as below.
library(readxl)
df <- read_excel("data/example-data-type.xlsx")Below is a print out of the data object. Are there any issues here?
df## # A tibble: 5 x 4
## id date loc temp
## <dbl> <dttm> <chr> <dbl>
## 1 1 2010-01-03 00:00:00 New York 42
## 2 2 2010-02-03 00:00:00 New York 41.4
## 3 3 2010-03-03 00:00:00 New York 38.5
## 4 4 2010-04-03 00:00:00 New York 41.1
## 5 5 2010-05-03 00:00:00 New York 39.8In the United States, it is common to use the date format MM/DD/YYYY while the rest of the world commonly use DD/MM/YYYY or YYYY/MM/DD. It is highly probable that the dates are 1st-5th March and not 3rd of Jan-May. You can validate data with external sources, e.g. say the temperature at New York during the two choices suggest that the dates are 1st-5th March.
The benefit of working with data grounded in the real world process is that there are generally means to sanity check. You can robustify your workflow by ensuring that you have an explicit check for the expected data type (and values) in your code.
In the code below, we write our expected types and further coerce some data types to what we want.
library(tidyverse)
read_excel("data/example-data-type.xlsx",
col_types = c("text", "date", "text", "numeric")) %>%
mutate(id = as.factor(id),
date = as.character(date),
date = as.Date(date, format = "%Y-%d-%m"))## # A tibble: 5 x 4
## id date loc temp
## <fct> <date> <chr> <dbl>
## 1 1 2010-03-01 New York 42
## 2 2 2010-03-02 New York 41.4
## 3 3 2010-03-03 New York 38.5
## 4 4 2010-03-04 New York 41.1
## 5 5 2010-03-05 New York 39.8read_csv("data/example-data-type.csv",
col_types = cols(id = col_factor(),
date = col_date(format = "%m/%d/%y"),
loc = col_character(),
temp = col_double()))## # A tibble: 5 x 4
## id date loc temp
## <fct> <date> <chr> <dbl>
## 1 1 2010-03-01 New York 42
## 2 2 2010-03-02 New York 41.4
## 3 3 2010-03-03 New York 38.5
## 4 4 2010-03-04 New York 41.1
## 5 5 2010-03-05 New York 39.8The checks (or coercions) ensure that even if the data are updated, you can have some confidence that any data type error will be picked up before further analysis.
3.1.2 Checking the data quality
Numerical or graphical summaries, or even just eye-balling the data, helps to uncover some data quality issues. Do you see any issues for the data below?
df2 <- read_csv("data/example-data-quality.csv",
col_types = cols(id = col_factor(),
date = col_date(format = "%m/%d/%y"),
loc = col_character(),
temp = col_double()))
df2## # A tibble: 9 x 4
## id date loc temp
## <fct> <date> <chr> <dbl>
## 1 1 2010-03-01 New York 42
## 2 2 2010-03-02 New York 41.4
## 3 3 2010-03-03 New York 38.5
## 4 4 2010-03-04 New York 41.1
## 5 5 2010-03-05 New York 39.8
## 6 6 2020-03-01 Melbourne 30.6
## 7 7 2020-03-02 Melbourne 17.9
## 8 8 2020-03-03 Melbourne 18.6
## 9 9 2020-03-04 <NA> 21.3There is a missing value in loc. Temperature is in Farenheit for New York but Celsius in Melbourne. You can find this out again using external sources.
Consider the soybean study conducted in Brazil (cite Lehner 2016). This study collected multiple traits of soybeans grown at multiple locations over years.
library(naniar)
data("lehner.soybeanmold", package = "agridat")
vis_miss(lehner.soybeanmold)
Inspecting the data reveals that there are a number of missing values for sclerotia and these values do not necessary appear missing at random. We could check if observational units that are missing values for sclerotia, have different yield say.
ggplot(lehner.soybeanmold, aes(sclerotia, yield)) +
geom_miss_point()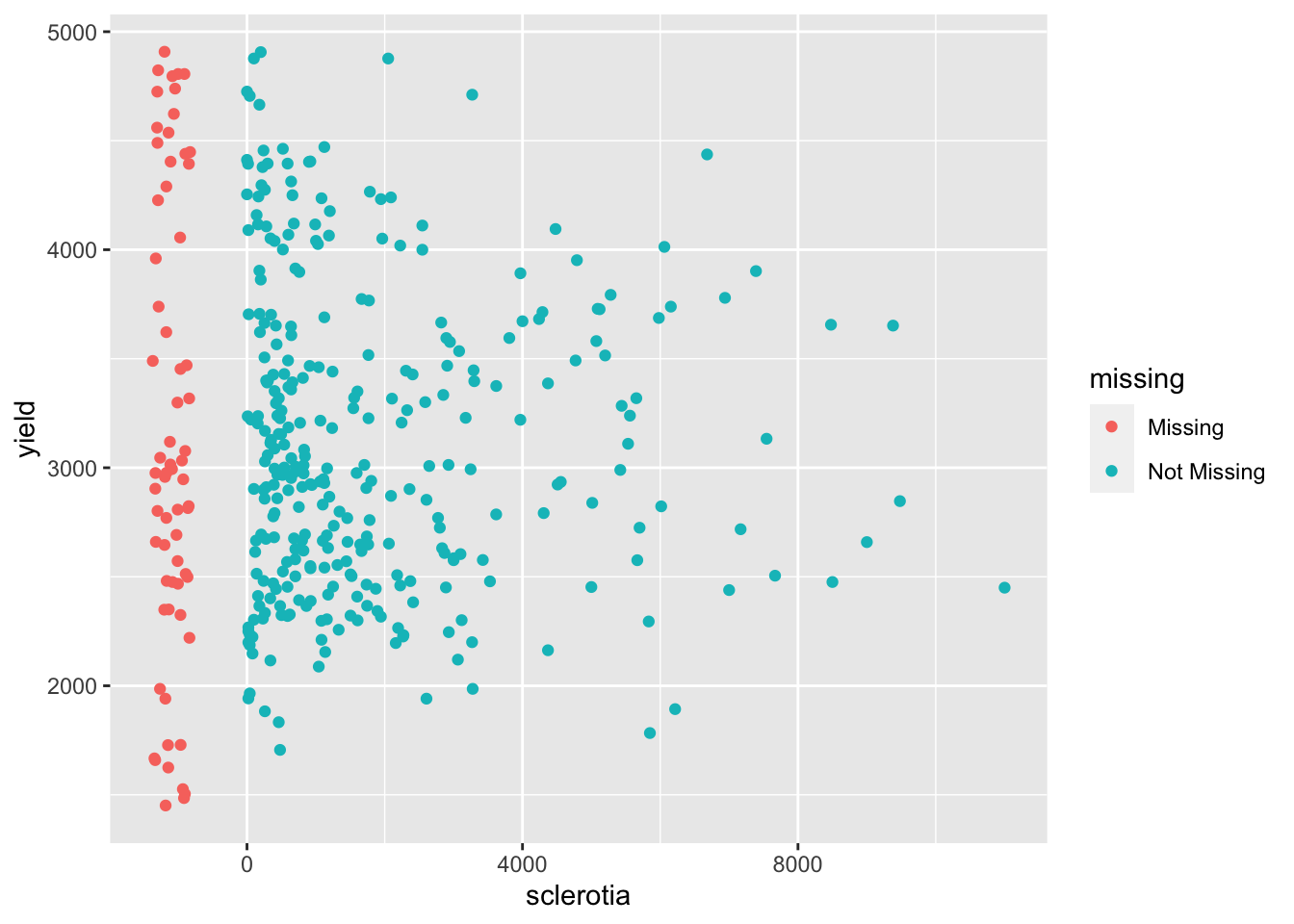
We could also compare the new data with old data.
library(inspectdf)
soy_old <- lehner.soybeanmold %>%
filter(year %in% 2010:2011)
soy_new <- lehner.soybeanmold %>%
filter(year == 2012)
inspect_cor(soy_old, soy_new) %>%
show_plot()## Warning: Columns with 0 variance found: year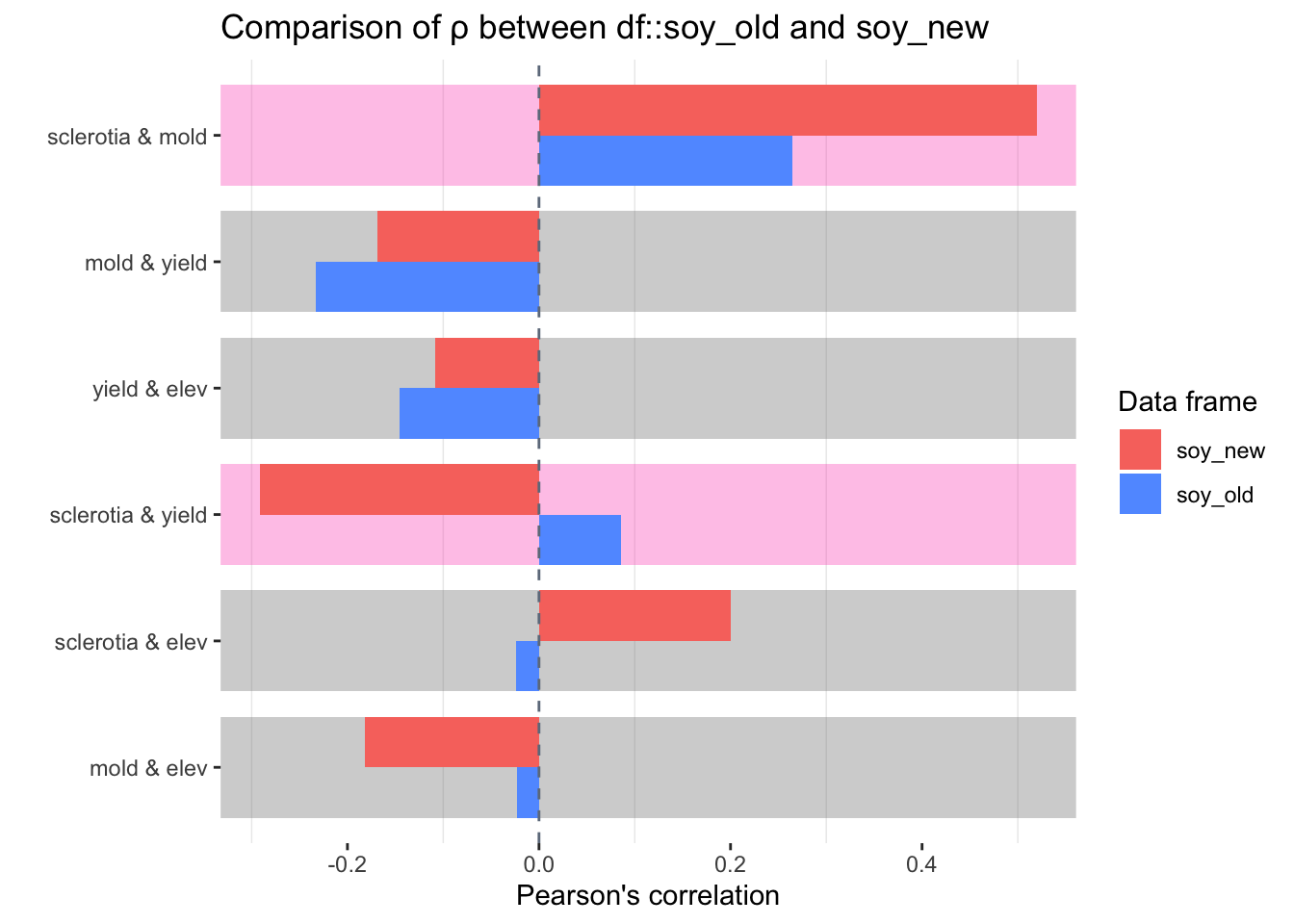
3.1.3 Check on data collection method
Next we study the data from ABS that shows the total number of people employed in a given month from February 1976 to December 2019 using the original time series.
library(readabs)
employed <- read_abs(series_id = "A84423085A") %>%
mutate(month = lubridate::month(date),
year = factor(lubridate::year(date))) %>%
filter(year != "2020") %>%
select(date, month, year, value) Do you notice anything?
employed %>%
ggplot(aes(month, value, color = year)) +
geom_line() +
ggtitle("1978 Feb - 2019 Dec") 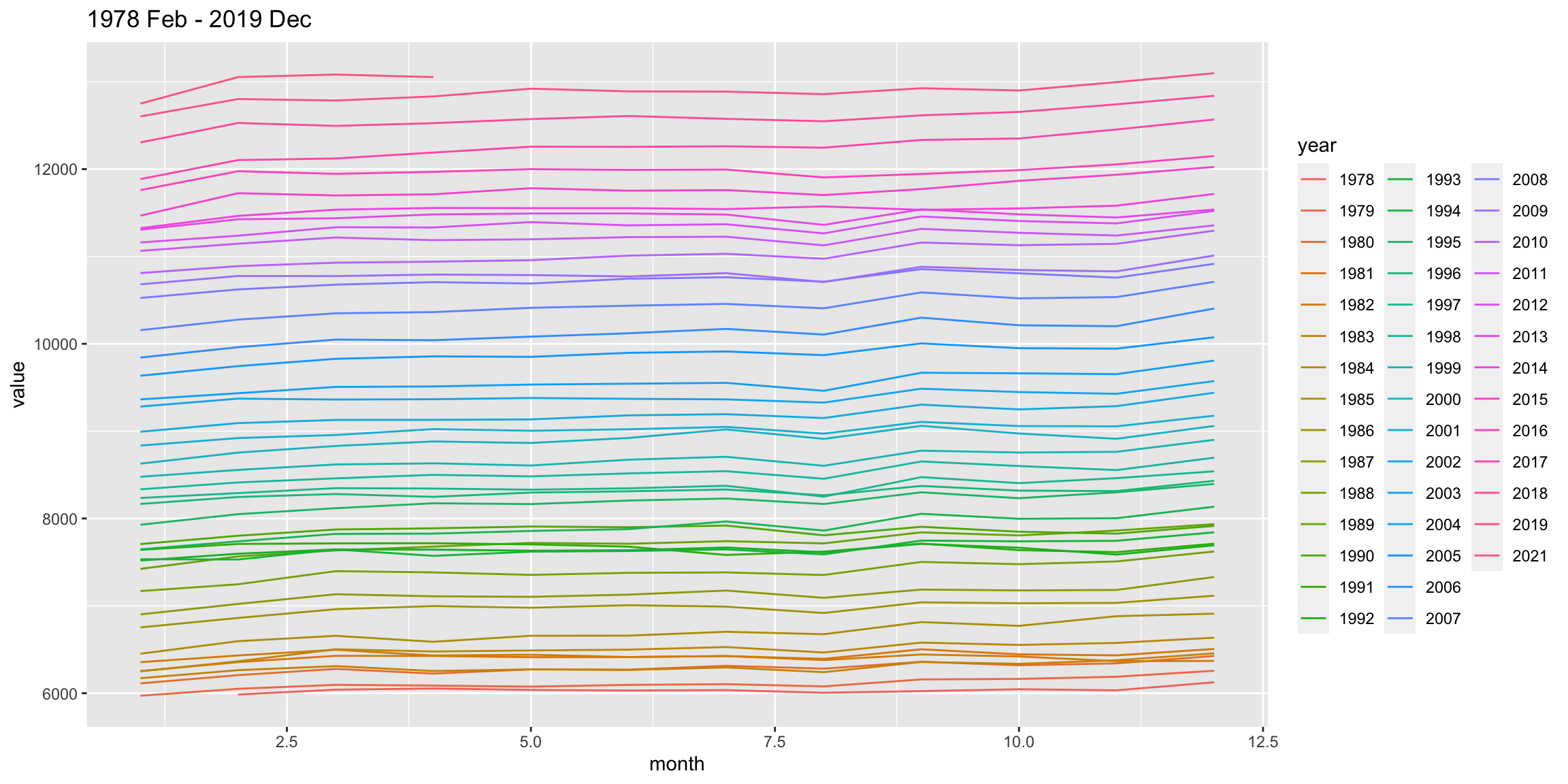
Why do you think the number of people employed is going up each year?
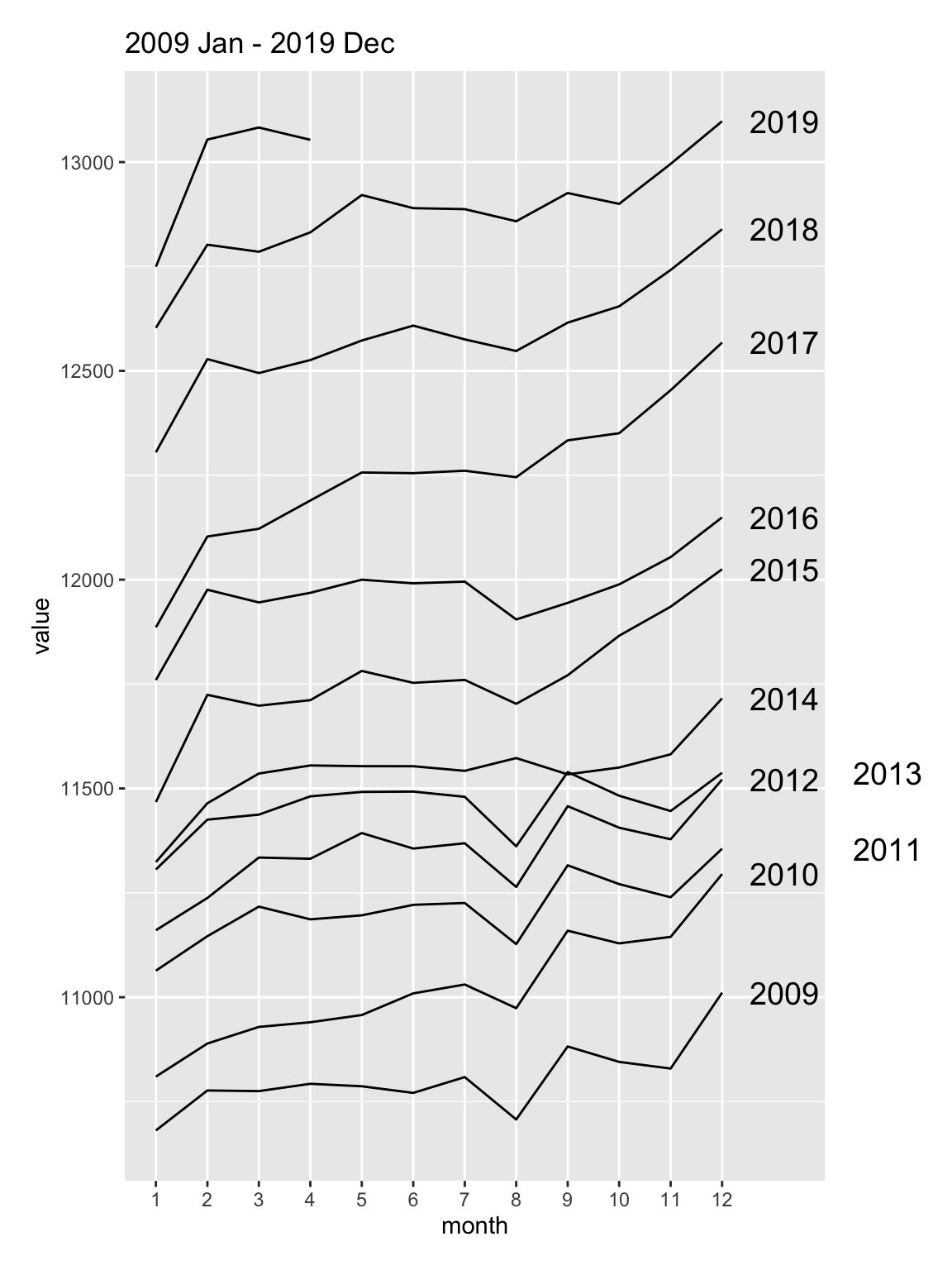
There’s a suspicious change in August numbers from 2014.
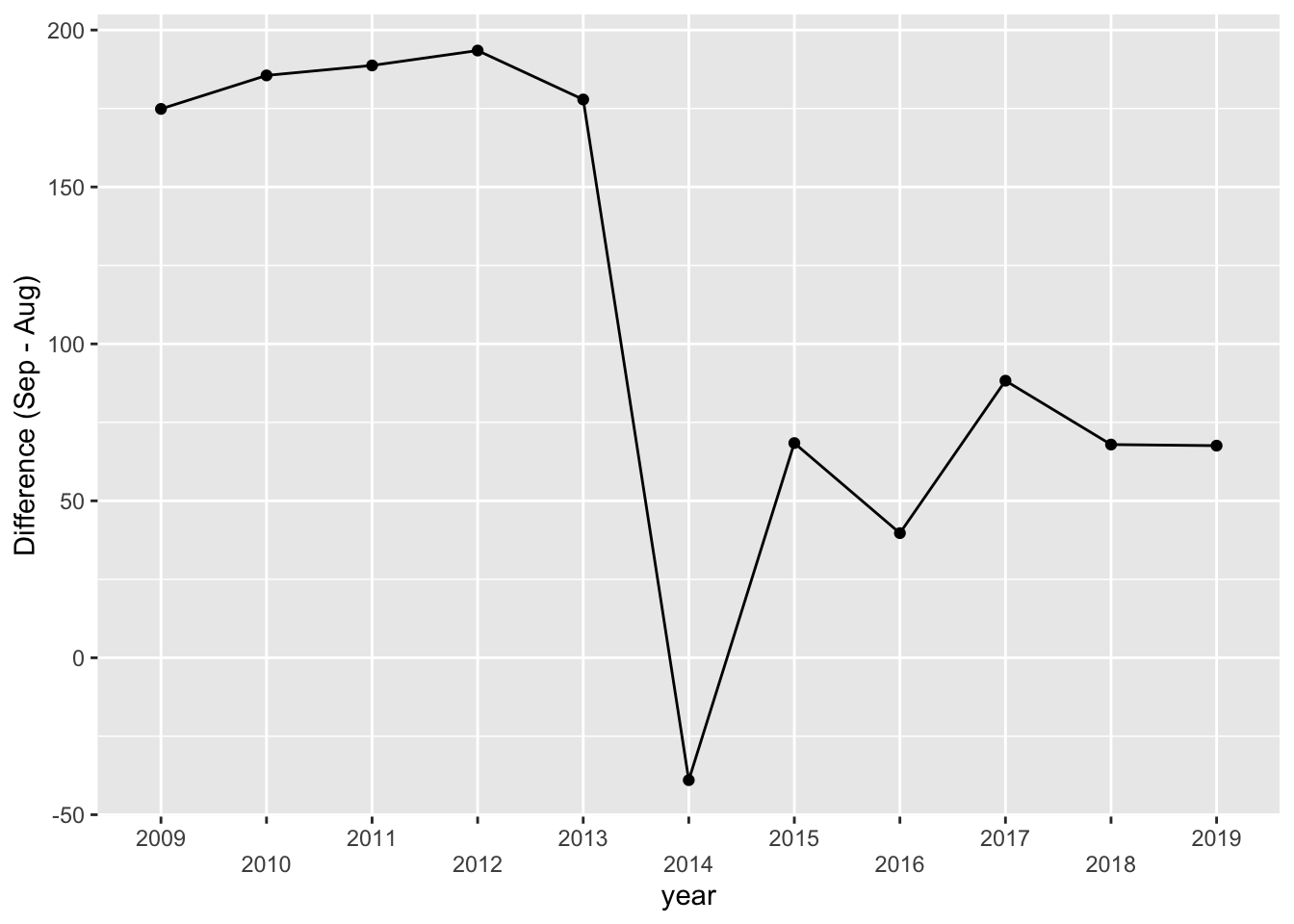
A potential explanation for this is that there was a change in the survey from 2014. Also see https://robjhyndman.com/hyndsight/abs-seasonal-adjustment-2/
Check if the data collection method has been consistent.
3.1.4 Check for experimental data
For experimental data, there would generally be some descriptions that include the experimental layout and any randomisation process of controlled variables (e.g. treatments) to units.
Consider the experiment below. The experiment tests the effects of 9 fertilizer treatments on the yield of brussel sprouts on a field laid out in a rectangular array of 6 rows and 8 columns.
df3 <- read_csv("data/example-experimental-data.csv",
col_types = cols(row = col_factor(),
col = col_factor(),
yield = col_double(),
trt = col_factor(),
block = col_factor()))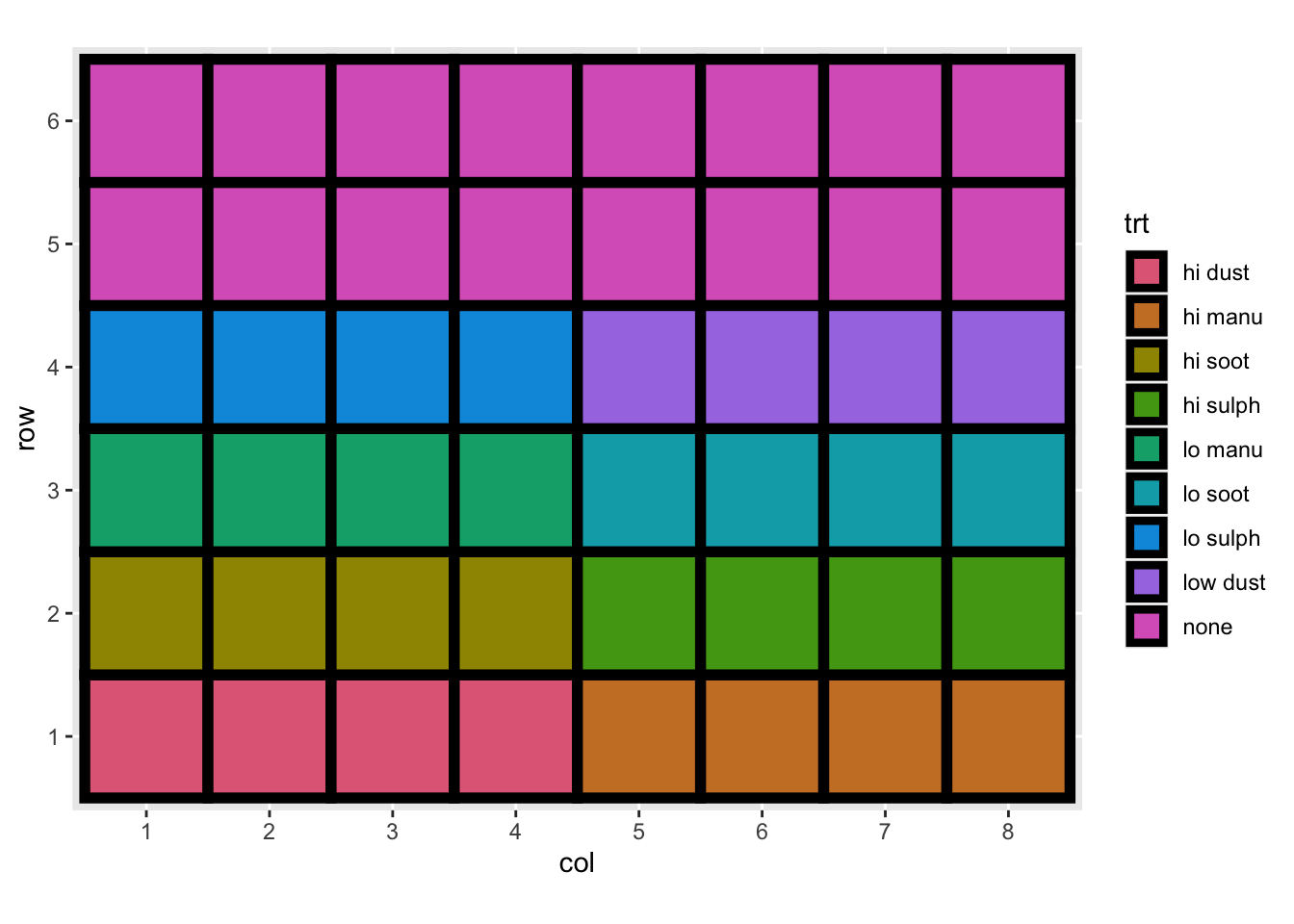
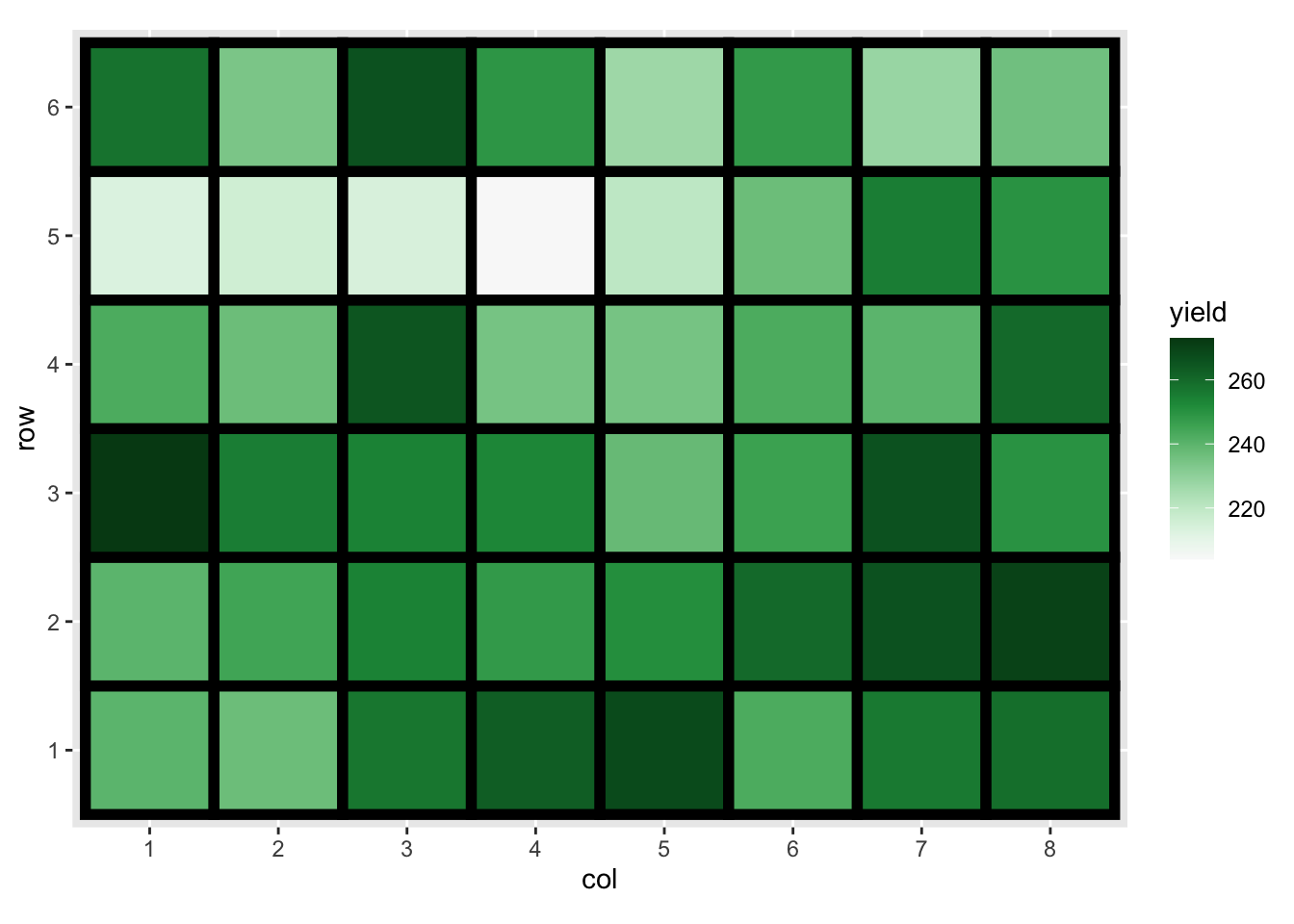
df3 %>%
mutate(trt = fct_reorder(trt, yield)) %>%
ggplot(aes(trt, yield)) +
geom_point(size = 4, alpha = 1 / 2) +
guides(x = guide_axis(n.dodge = 2))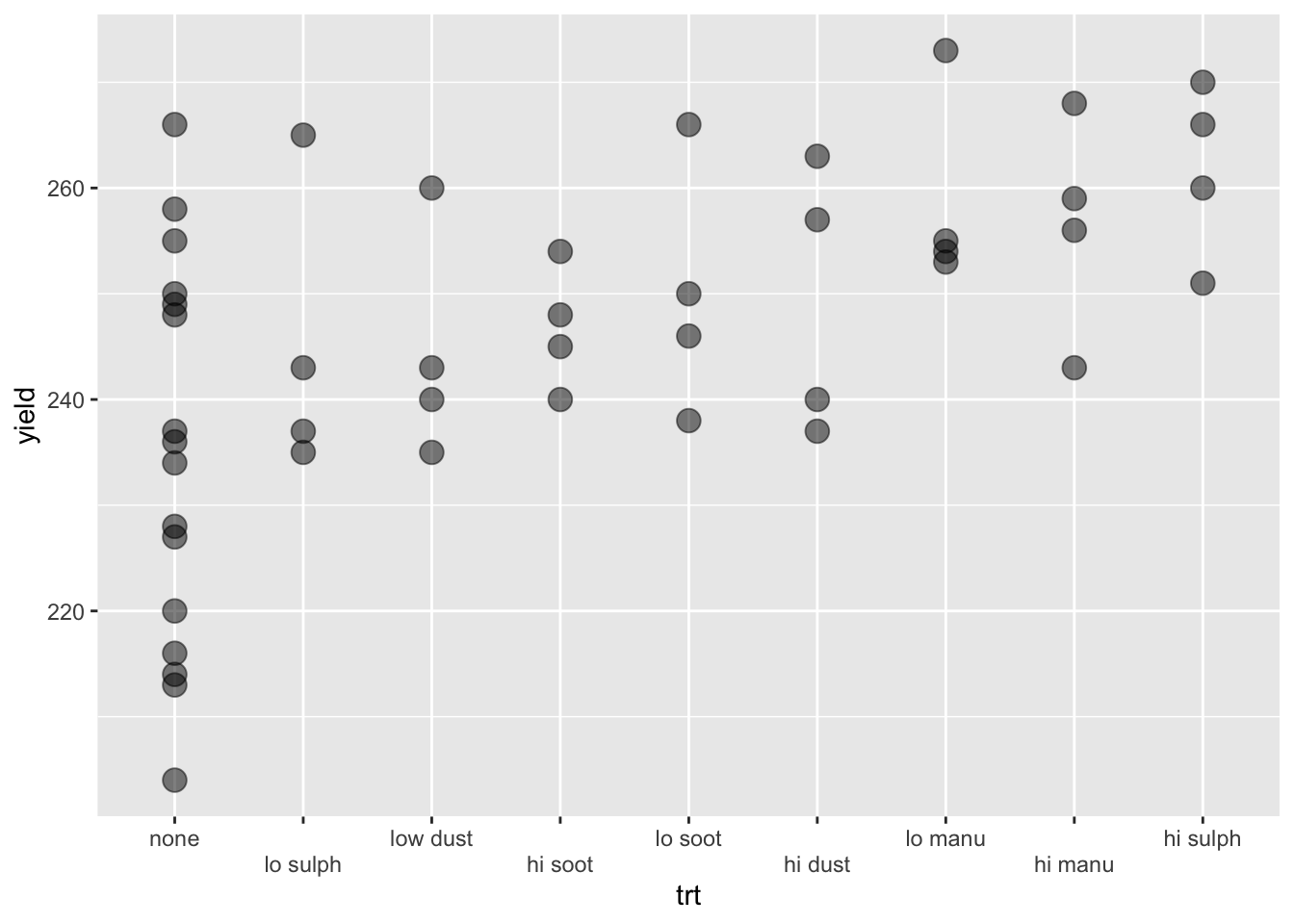
High sulphur and high manure seems to best for the yield of brussel sprouts. Any issues here?
3.2 Model formulation
Note: there are variety of ways to do IDA and you don’t need to prescribe to what we show you.